![]()
![]()
![]()
![]()
![]()
![]() Previous: Einführung PHP
Up: Einführung PHP
Next: PHP & HTML
Previous: Einführung PHP
Up: Einführung PHP
Next: PHP & HTML
![]()
![]()
![]()
![]()
![]()
![]() Previous: Einführung PHP
Up: Einführung PHP
Next: PHP & HTML
Previous: Einführung PHP
Up: Einführung PHP
Next: PHP & HTML
PHP![[*]](footnote.png) ist eine serverseitige, in
HTML eingebettete Scriptsprache - oder mit anderen
Worten: PHP-Scripte werden auf dem Server ausgeführt, im Gegensatz z.B. zum üblichen
JavaScript und Java. Der Programmcode wird in die
HTML-Quelldatei geschrieben und somit i.A. nicht in einer extra ,,PHP-Datei`` abgelegt. Als Script werden Programme bezeichnet, die keine eigenständigen Programme
sind, weil sie nicht kompliziert genug sind und andere Programme benötigen, um ausgeführt
zu werden.
ist eine serverseitige, in
HTML eingebettete Scriptsprache - oder mit anderen
Worten: PHP-Scripte werden auf dem Server ausgeführt, im Gegensatz z.B. zum üblichen
JavaScript und Java. Der Programmcode wird in die
HTML-Quelldatei geschrieben und somit i.A. nicht in einer extra ,,PHP-Datei`` abgelegt. Als Script werden Programme bezeichnet, die keine eigenständigen Programme
sind, weil sie nicht kompliziert genug sind und andere Programme benötigen, um ausgeführt
zu werden.
Im Gegensatz zu HTML und JavaScript erscheint der eigentliche PHP-Code i.A. nicht auf der
Clientseite, d.h. der Quellcode, den man sich im Browser auch ansehen kann, enthält für
gewöhnlich keinen PHP-Code. Der
HTML-Code wird beim Abruf der Webseite, wie bei normalen Seiten auch, 1:1 an den Client
geschickt; der PHP-Code wird durch den Server ausgeführt und die Ausgabe dann, zusammen
mit den nicht interpretierten HTML-Scriptanteilen, an den Client gesandt. Es ist auch
möglich, PHP-Scripte ganz ohne (sichtbare) Ausgabe laufen zu lassen - was durchaus sinnvoll
sein kann.
Immer wenn man sich fragt, ob etwas möglich ist, ist zu überlegen, ob dazu eine Aktion auf dem Server (wo die Webseite liegt) oder auf dem Client (wo die Webseite angezeigt wird) notwendig ist. Z.B.: Ist es möglich, mit einem PHP-Befehl die aktuelle Webseite auszudrucken? Die Antwort ist ganz einfach: Damit auf dem Client die Seite ausgedruckt wird, muß dem Browser ein Befehl übermittelt werden. Da PHP aber auf dem Server ausgeführt wird, kann es diesen Befehl folglich nicht selbst in die Tat umsetzen. Auf dem Client wird aber z.B. JavaScript ausgeführt, das einen Befehl anbietet, der die Seite ausdruckt (sofern JavaScript aktiviert ist). Für viele andere Aktionen ist aber nicht einmal JavaScript nötig.
Im vorigen Kapitel wurde SQL beschrieben, jetzt wird PHP erklärt. Dies sind zwei
voneinander unabhängige Sprachen, die erst einmal nichts miteinander zu tun
haben! Auch wenn es Funktionen in beiden Sprachen gibt, die ähnlich heißen, können
sie sich doch deutlich unterscheiden. Im weiteren Verlauf wird gezeigt, wie man die beiden
Programmiersprachen zusammenführt. Auch dann muß man sich weiter im Klaren darüber sein,
was SQL und was PHP ist.
1 <? echo "Hello world!"; ?>
2 <?php echo "Hello world!"; ?>
3 <script language="php">
echo "Hello world!";
</script>
Die erste Möglichkeit ist die kürzeste und damit bei vielen die beliebteste (wer ist nicht
gerne faul?). Sie ist allerdings nicht XML-konform, so daß später Probleme auf den Programmierer zukommen können,
wenn man sie benutzt. Außerdem gibt es Server, die diese Variante nicht erkennen. Ich benutze
immer die zweite Variante; sie ist kurz, aber dennoch XML-konform.
Die Sprache PHP ist hauptsächlich von C, aber auch von Java und Perl (die ihrerseits von C
beeinflußt wurden) geprägt. Aber auch für Pascal/Delphi-Programmierer ist die Sprache nicht
schwer zu erlernen.
Grundsätzlich gilt (merken!): Eine Anweisung wird immer mit einem `;` abgeschlossen
und eine Funktion bzw. einen Funktionsaufruf erkennt man an runden Klammern `()`.
genannt. Bei den Anführungsstrichen gibt es
zwei verschiedene: einmal das einfache ,,'`` und das doppelte ,,"``
. Es gibt auch einen Unterschied zwischen den beiden: Bei den doppelten Anführungsstrichen
versucht der Server, den Text zu interpretieren; bei den einfachen hingegen behandelt er
ihn nicht speziell, sondern gibt ihn z.B. direkt aus. Weitere Erklärungen zu Anführungszeichen
finden sich in Kapitel 8.2.6.4.
$var = 123; echo 'Die Variable $var hat den Wert 123!\n'; echo "Die Variable $var hat den Wert 123!\n";Das erste echo gibt ,,Die Variable $var hat den Wert 123!
\n`` aus, das
zweite hingegen ,,Die Variable 123 hat den Wert 123!`` mit folgendem
Zeilenumbruch.
echo "Say \"Hello World\" my friend";Die Ausgabe bei diesem echo ist ``Say ``Hello World!`` my friend`` . Wie man sieht, müssen doppelte Anführungsstriche, die ausgegeben werden sollen, besonders gekennzeichnet werden. Dieses Vorgehen nennt man Escapen
. Es ist insbesondere für das Ausgeben
von HTML-Quelltext in Verbindung mit echo und print nötig und kann u.U. zu
Problemen führen, wenn man vergißt, in allen Teilstrings zu escapen. Siehe auch Kapitel
13 (Fehlersuche).
$var1 = "Hallo"; $var2 = "Welt!"; echo $var1," ",$var2; echo $var1." ".$var2; print ($var1." ".$var2); $res = print ($var1." ".$var2);
$a = $b;
Wenn beide Operanden bei der Division vom Typ integer (ganzzahliger Wert) sind, ist das Ergebnis ebenfalls integer. Ist ein Operand eine Kommazahl, wird das Ergebnis auch eine Kommazahl.
Befehle wie `$a = $a + 5` kann man etwas abkürzen:
$a += 5; // entspricht $a = $a + 5; $a *= 2; // entspricht $a = $a * 2; $i++; // entspricht $i = $i + 1; $i--: // entspricht $i = $i - 1;
$a = "Hello "; $b = $a . "World!"; // jetzt ist $b = "Hello World!"Auch hier lassen sich Befehle der Form `$a = $a . ``noch etwas Text``` abkürzen:
$a = "Hello "; $a .= "World!";
|
|
Der Unterschied zwischen den beiden UND und ODER liegt in deren Priorität verglichen mit anderen Operatoren.
Der Fachbegriff hierfür lautet Kurzschlußlogik, weil die Sprache (in diesem Fall PHP) erkennt, daß der boolesche Ausdruck nicht mehr wahr werden kann und deshalb gleich abbricht (nur die Evaluierung, nicht das Skript!).
Das ist wichtig zu wissen, denn so kann man bestimmte Voraussetzungen abfragen, bevor man z.B. eine Funktion aufruft oder eine Abfrage startet, die von einem Parameter abhängt - und das alles z.B. in einem Ausdruck!
Ganz analog verhält es sich bei ODER-Verknüpfungen: Wird hier einer der booleschen Ausdrücke wahr, werden die anderen nicht mehr bearbeitet. Diesen Umstand kann man z.B. ausnutzen, indem man häufiger wahr werdende oder weniger Laufzeit in Anspruch nehmende Ausdrücke weiter vorne (links) hinschreibt.
Zu beachten ist, daß diese Kurzschlußlogik nicht bei den bitweisen Operatoren & und | zum Einsatz kommt.
echo "Noch kein Kommentar!"; /* Dies ist ein Kommentar, der auch ueber mehrere Zeilen gehen kann */ // Dies ist wieder ein Kommentar, // der jeweils bis zum Ende der Zeile geht echo "Kein Kommentar mehr!";Die erste und die letzte Zeile sind Befehle, der Rest sind Kommentare.
| int, integer | Integer |
| real, double, float | Double |
| boolean | Boolean |
| string | String |
| array | Array |
| object | Objekt |
Wird einer Integervariablen ein Wert außerhalb des oben genannten Wertebereichs zugewiesen, erfolgt die Umwandlung in den Typ ,double`.
Man kann Zahlen nicht nur in dem uns geläufigen Dezimalsystem (Basis: 10) eingeben. Es gibt auch noch das hexadezimale System (Basis: 16) und Oktalsystem (Basis: 8). Damit PHP weiß, was wir meinen, wird bei Hexadezimalzahlen ein ,,0x`` und bei Oktalzahlen eine ,,0`` vorangestellt. Diese Zahlensysteme werden häufig wegen ihrer stärkeren Hardware-Nähe benutzt. Für uns sind sie im Moment eher weniger interessant.
Betrachten wir als erstes die doppelten Anführungszeichen (``). Um
z.B. innerhalb der Anführungszeichen eines echo- oder
print-Befehls ein Anführungszeichen zu schreiben (so, daß es
ausgegeben wird), muß dieses mit einem Backslash (\)
versehen werden, weil es sonst den String beenden würde. Buchstaben mit einem
vorangestellten Backslash werden als ,,escaped
characters`` bezeichnet. Eine Übersicht der escaped characters gibt es in
Tabelle 8.5.
|
Auch bei den einfachen Anführungszeichen gibt es escaped characters: Es können genau zwei verwendet werden, nämlich \` (einfaches Anführungszeichen) und \\ (Backslash).
Ein String ist im Prinzip ein Array aus Zeichen. Dadurch kann man problemlos auf einzelne Zeichen zugreifen. Z.B. wird mit $string[n] auf das n-te Zeichen im String zugegriffen. Erfordert eine Funktion als Parameter nun unbedingt ein richtiges Array, muß der String erst konvertiert werden. Die einfachste mir bekannte Möglichkeit ist mit Hilfe einer kleinen for-Schleife (hier in eine Funktion verpackt):
/**
* Die Funktion wandelt einen String in ein Array um
* und gibt dieses zurück
*
* @param string Der Text, der umgewandelt werden soll
* @return array Array mit den einzelnen Buchstaben
* des Textes
*/
function str2array($text){
$ar = array();
for ($i=0; $i<strlen($text); $i++){
$ar[] = $text[$i];
}
return $ar;
}
Die bisher unbekannten Befehle sollen erstmal nicht weiter stören; sie werden weiter unten erklärt. Mehr zu Funktionen im Kapitel 8.7.
Ein kleines Beispiel zu den bis hierher beschriebenen Datentypen:
Die Funktion int floor(float number) schneidet die Nachkommastellen
ab und gibt einen Integer zurück.
$a = 1234; // $a ist ein Integer
$b = (double) $a; // $b ist ein Double mit dem Wert 1234
$a = 0123; // Oktalzahl (entspricht 83 dezimal)
$a = 0xbad; // Hexadezimalzahl
// (entspricht 2989 dezimal)
echo floor((0.1+0.7)*10); // Ausgabe ist 7
Die ersten Werte sind noch einfach nachzuvollziehen. Beim letzten ist es allerdings schon schwieriger. Eigentlich würde man als Ausgabe doch eher eine ,,8`` erwarten. Wieso aber eine ,,7`` ausgegeben wird, kann man in Worte gefaßt einfach Rundungsfehler nennen. Die längere Version: Computer rechnen intern im Dualsystem; bei ganzen Zahlen ergeben sich keine Rundungsfehler beim Wandeln von Dezimalsystem in das Dualsystem. Bei der Darstellung als Fließkommazahl (float) kommt es aber gelegentlich schon zu Rundungsfehlern. In diesem Beispiel tritt gerade so einer auf.
Wenn es zu keinen Rundungsfehlern kommen darf, muß man Integer als Datentyp nehmen. In der Regel ist das auch kein großes Problem, zum Beispiel kann man Preise einfach in Euro Cent abspeichern und schon braucht man keine Nachkommastellen mehr.
Das soll uns aber nicht weiter stören. Ich habe dieses Beispiel hier nur zur allgemeinen Verwirrung eingefügt ;-) .
$monat[1] = "Januar"; $monat[2] = "Februar"; $monat[3] = "Maerz"; $monat[4] = "April"; $monat[5] = "Mai"; $monat[6] = "Juni"; $monat[7] = "Juli"; $monat[8] = "August"; $monat[9] = "September"; $monat[10] = "Oktober"; $monat[11] = "November"; $monat[12] = "Dezember";Oder als Tabelle:
| Zeile | Name |
|---|---|
| 1 | Januar |
| 2 | Februar |
| 3 | Maerz |
| 4 | April |
| 5 | Mai |
| 6 | Juni |
| 7 | Juli |
| 8 | August |
| 9 | September |
| 10 | Oktober |
| 11 | November |
| 12 | Dezember |
Bei dieser Tabelle spricht man von einer 1-dimensionalen Tabelle, weil eine Koordinate (die Zeilennummer) ausreicht, um jedes Feld eindeutig zu bestimmen. Der Index (=Zeilennummer) wird in eckigen Klammern hinter dem Array-Namen angegeben.
Wenn man neben dem Monatsnamen auch die Anzahl der Tage im jeweiligen Monat
abspeichern will, braucht man eine 2-dimensionale Tabelle:
| Zeile | Name | Tage |
|---|---|---|
| 1 | Januar | 31 |
| 2 | Februar | 28 |
| 3 | Maerz | 31 |
| 4 | April | 30 |
| 5 | Mai | 31 |
| 6 | Juni | 30 |
| 7 | Juli | 31 |
| 8 | August | 31 |
| 9 | September | 30 |
| 10 | Oktober | 31 |
| 11 | November | 30 |
| 12 | Dezember | 31 |
Und das ganze in PHP:
$monat[1]["Name"] = "Januar"; $monat[1]["Tage"] = 31; $monat[2]["Name"] = "Februar"; $monat[2]["Tage"] = 28; $monat[3]["Name"] = "Maerz"; $monat[3]["Tage"] = 31; $monat[4]["Name"] = "April"; $monat[4]["Tage"] = 30; $monat[5]["Name"] = "Mai"; $monat[5]["Tage"] = 31; $monat[6]["Name"] = "Juni"; $monat[6]["Tage"] = 30; $monat[7]["Name"] = "Juli"; $monat[7]["Tage"] = 31; $monat[8]["Name"] = "August"; $monat[8]["Tage"] = 31; $monat[9]["Name"] = "September"; $monat[9]["Tage"] = 30; $monat[10]["Name"] = "Oktober"; $monat[10]["Tage"] = 31; $monat[11]["Name"] = "November"; $monat[11]["Tage"] = 30; $monat[12]["Name"] = "Dezember"; $monat[12]["Tage"] = 31;
In diesem Beispiel sehen wir zwei wichtige Eigenschaften von Arrays in PHP:
Zum einen werden bei mehreren Dimensionen die Indizes einzeln in eckigen
Klammern hinter dem Array-Namen angegeben. Zum anderen kann man bei PHP, im
Gegensatz zu gewöhnlichen Programmiersprachen, für die Indizes beliebige
skalare Datentypen
verwenden. Dadurch werden sogenannte assoziative Arrays möglich.
Wie kann man sich n-dimensionale Arrays vorstellen? Bei 3 Dimensionen ist es noch relativ einfach: Nimmt man mehrere 2-dimensionale Arrays und legt diese aufeinander, hat man die 3. Dimension. Ab der 4. Dimension wird das schon etwas schwerer. Aber im Zweifelsfall muß man sich die Arrays nicht vorstellen, sondern nur Daten in ihnen speichern.
In PHP gibt es neben Variablen auch Konstanten. Bei Konstanten ist, wie der Name
schon sagt, der Wert nicht veränderlich, außerdem sind sie überall abrufbar. Weitere
Unterschiede zu Variablen sind, daß Konstanten nur Werte von
Primitivtypen annehmen können und überhaupt
grundsätzlich von Variablen unterschieden werden müssen: Konstantennamen bestehen nur aus
alphanumerischen Zeichen, werden also nicht mit einem Dollarzeichen eingeleitet,
und sind völlig unabhängig von Variablen gleichen Namens. Um die Unterscheidung deutlich
zu machen, nimmt man daher für die Namen von Konstanten häufig nur Großbuchstaben.
Konstanten werden auch grundsätzlich anders definiert, nämlich mittels einer PHP-Funktion
namens define(). Als ersten Parameter übergibt man dieser Funktion den Namen der
zu definierenden Konstante und als zweiten deren Wert.
Folgendes Beispiel sollte das Gesagte verdeutlichen:
$var = "variabler Wert";
define("CONST", "konstanter Wert");
$var = CONST;
echo $var;
$CONST = "Problem?";
Der Beispielcode würde zu keinem Problem führen, denn CONST hat
weiterhin den Wert, der der Konstante mittels define() zugewiesen wurde;
gleichzeitig hat durch die Zuweisung in Zeile 3 auch $var den Wert der
Konstante angenommen.
Durch die letzte Zeile wird einfach eine neue Variable angelegt, die denselben Namen hat wie die Konstante. So sollte man jedoch ausdrücklich nicht programmieren! Es sollte nicht allzu schwierig sein, einen anderen Namen zu finden ...
Zu einem Fehler würde es erst dann kommen, wenn man in der letzten Zeile das Dollarzeichen entfernte. Dann nämlich würde etwas versucht, was per definitionem nicht erlaubt ist: einer Konstanten einen neuen Wert zuweisen. Da in PHP für die Definition einer Konstanten jedoch eine Funktion benutzt wird, kommt man auch nicht so schnell durcheinander.
$objekt = "Auto";
$$objekt = "Cabrio"; // $Auto = "Cabrio"
${$objekt} = "Cabrio"; // alternative Syntax
Natürlich darf man bei diesem Vorgehen nicht gegen die Regeln für die Vergabe von Variablennamen verstoßen, d.h. der String, den man als Namen einer anderen Variable benutzen möchte, darf z.B. nicht mit einer Zahl beginnen, da der Name der neuen Variable dann ungültig wäre.
Wirklich interessant wird es aber erst, wenn man den Wert bestehender Variablen mit
festen Strings kombiniert um damit einen neuen Variablennamen zu erzeugen:
$objekt = "Auto";
${"mein$objekt"} = "Cabrio"; // $meinAuto = "Cabrio";
Innerhalb der geschweiften Klammern macht man hier von dem Umstand Gebrauch, daß Variablen in Strings, die in doppelten Anführungsstrichen stehen, ausgewertet werden. Natürlich kann man auch mit dem Stringoperator . arbeiten.
Bei Arrays ist schließlich noch zu beachten, daß $$array[0] vielleicht nicht immer das macht, was man erwartet - will man nun den ersten Eintrag aus $array als Namen für eine andere Variable benutzen oder nicht vielmehr den ersten Eintrag aus dem Array betrachten, dessen Name derselbe ist wie der Wert von $array? Diese Problematik läßt sich leicht umschiffen, indem man die alternative Syntax mit den geschweiften Klammern benutzt, d.h. entweder die eckigen Klammern mitsamt der Indexangabe (z.B. [0]) in die geschweiften Klammern schreiben oder dahinter.
|
So kommt es auch, daß jeder String bezüglich == gleich der Integerzahl 0 ist, auch der Leerstring ````. Daß das zu unerwünschten Effekten führen kann (Intentionsfehler), zeigt ein Codebeispiel in Kapitel 9.4.1.
Umgehen läßt sich dieses Problem, indem man zusätzlich auf Typgleichheit überprüft. Dazu gibt es in PHP die Operatoren === (gleicher Wert und Typ) und !== (weder gleicher Wert noch Typ).
if (expr) statement`expr` ist Platzhalter für die Bedingung und `statement` für den Befehl, der bei erfüllter Bedingung ausgeführt werden soll. Als Beispiel:
if ($a>$b) print "a ist groesser als b";Falls man mehr als einen Befehl hat, der ausgeführt werden soll, so ist auch das möglich. Man muß die Befehle nur in geschweifte Klammern einschließen:
if ($a>$b) {
print "a ist groesser als b";
$b = $a;
}
Man kann natürlich auch nur einzelne Befehle in geschweifte Klammern einschließen (und sei es nur, um einheitlich zu programmieren, oder Fehler beim Erweitern zu vermeiden).
if ($a>$b) print "a ist groesser als b"; if ($a<=$b) print "a ist nicht groesser als b";...oder aber den ELSE-Zweig verwenden:
if ($a>$b) print "a ist groesser als b"; else print "a ist nicht groesser als b";
Analog zu IF kann man auch hier mehrere Befehle pro Zweig (IF, ELSE) angegeben; in diesem Fall müssen diese Anweisungen in geschweiften Klammern geschrieben werden. Kombinationen (z.B. geschweifte Klammern bei IF, aber keine bei ELSE) sind möglich.
if ($a > $b) {
print "a ist groesser als b";
} elseif ($a == $b) {
print "a ist gleich b";
} else {
print "a ist kleiner als b";
}
<?php if ($a<$b): ?> <h1>a ist kleiner als b</h1> <?php endif; ?>Der HTML-Text wird nur dann ausgegeben, wenn die Bedingung ,,A kleiner B`` erfüllt ist. Es können auch mehrere HTML-Zeilen benutzt werden. Hier machen geschweifte Klammern natürlich keinen Sinn, wie auch im folgenden Fall.
(Bedingung?Rückgabewert wenn true:Rückgabewert wenn false)An einem konkreten Beispiel:
<?php echo ($a < $b?"a ist kleiner als b":""); ?>Es gibt Stellen, wo sich diese Syntax sehr gut eignet (z.B. bei der Funktion printf, die in Kapitel 8.8.1 beschrieben wird). Zu häufige Anwendung führt aber oft auch zu sehr schlecht lesbarem Code.
WHILE (expr) statementDie Bedeutung der WHILE-Schleife ist einfach: Solange die Bedingung `expr` erfüllt ist, wird die Anweisung `statement` ausgeführt. Falls die Bedingung von Anfang an nicht erfüllt ist, wird die Anweisung überhaupt nicht ausgeführt. Analog zu IF müssen mehrere Anweisungen, die zur selben WHILE-Schleife gehören, in geschweifte Klammern eingeschlossen werden.
Man kann auch die alternative Syntax nehmen:
WHILE (expr) : statement ... ENDWHILE;Das Ergebnis der folgenden Beispiele ist identisch; beide geben die Zahlen von 1 bis 10 aus.
/* Beispiel 1 */
$i=1;
while ($i<=10) {
print $i++; // $i wird erst ausgegeben und
// dann inkrementiert
// Inkrement = Nachfolger
// = um eins erhoeht (bei Zahlen)
}
/* Beispiel 2 */
$i=1;
while ($i<=10):
print $i;
$i++;
endwhile;
$i=0;
do {
print $i;
} while ($i>0); // $i wird genau einmal ausgegeben
Für Pascal/Delphi-Kenner:
sind die kompliziertesten
Schleifen in PHP. Die Syntax ist identisch mit der in C:
FOR (expr1; expr2; expr3) statementDer erste Ausdruck `expr1` wird genau einmal, am Anfang, ausgeführt. Damit initialisiert man in der Regel die Variable.
Analog zu IF müssen mehrere Anweisungen, die zur selben FOR-Schleife gehören, in geschweifte Klammern eingeschlossen werden.
Die FOR-Schleife kann im Prinzip auch mit einer WHILE-Schleife nachgebildet werden. Allgemein ausgedrückt (mit den oben verwendeten Bezeichnern) sähe das dann so aus:
expr1;
while (expr2){
statement
expr3;
}
Die folgenden Beispiele geben jeweils die Zahlen von 1 bis 10 aus:
/* Beispiel 1 */
for ($i=1; $i<=10; $i++) {
print $i;
}
/* Beispiel 2 */
for ($i=1;;$i++) {
if ($i > 10) {
break;
}
print $i;
}
/* Beispiel 3 */
$i=1;
for (;;) {
if ($i>10) {
break;
}
print $i;
$i++;
}
/* Beispiel 4 */
$i=1;
while ($i<=10){
print $i;
$i++;
}
Das erste Beispiel ist natürlich das geschickteste. Im vierten Beispiel ist die
FOR-Schleife mit Hilfe von WHILE nachgebildet worden. Wir sehen als
erstes die Initialisierung ($i wird auf 1 gesetzt). Die WHILE-Schleife
läuft so lange, wie die Laufbedingung erfüllt ist ($i muß kleiner/gleich 10
sein). Dann kommt die eigentliche Anweisung (Ausgabe der Variablenwerte) und als letztes wird
$i inkrementiert.
Mit break wird die aktuelle Schleife verlassen.
Hier zwei Beispiele, die dasselbe Ergebnis ausgeben - einmal mit einer Reihe von IF-Anweisungen und einmal mit einer SWITCH-Anweisung gelöst:
/* Beispiel 1 */
if ($i == 0) {
print "i ist gleich 0";
}
if ($i == 1) {
print "i ist gleich 1";
}
/* Beispiel 2 */
switch ($i) {
case 0:
print "i ist gleich 0";
break;
case 1:
print "i ist gleich 1";
break;
}
Es ist wichtig zu wissen, wie die SWITCH-Anweisung arbeitet, um Fehler zu vermeiden. Bei der SWITCH-Anweisung wird Zeile für Zeile (wirklich, Anweisung für Anweisung!) abgearbeitet. Am Anfang wird kein Code ausgeführt. Nur dann, wenn eine CASE-Anweisung mit einem Wert gefunden wird, der gleich dem Wert des SWITCH-Ausdruckes ist, fängt PHP an, die Anweisungen auszuführen. PHP fährt fort, die Anweisungen bis an das Ende des SWITCH-Blockes auszuführen oder bis es das erste Mal auf eine BREAK-Anweisung stößt. Wenn man keine BREAK-Anweisung an das Ende einer CASE-Anweisung schreibt, fährt PHP fort, Anweisungen über den folgenden Fall auszuführen. Z.B.:
/*Beispiel 3 */
switch ($i) {
case 0:
print "i ist gleich 0";
case 1:
print "i ist gleich 1";
}
Falls $i gleich 0 sein sollte, würden beide Anweisungen ausgegeben, was in diesem Fall nicht erwünscht wäre.
Dieses Verhalten kann aber auch bewußt genutzt werden, wie man in den folgenden Fällen sieht. Solcher Code wird allerdings sehr schnell unleserlich, weil er sich anders verhält, als man es auf den ersten Blick erwartet. Von daher sollte man das entweder vermeiden oder ein paar Kommentare einfügen.
/*Beispiel 4 */
switch($i) {
case 0:
print "i ist gleich 0";
break;
case 1:
case 2:
print "i ist gleich 1 oder 2";
}
/*Beispiel 5 */
switch($i) {
case 0:
print "i ist gleich 0";
case 1:
case 2:
print "i ist gleich 0 oder 1 oder 2";
}
Ein spezieller Fall ist der default-Fall. Dieser Fall trifft auf alles zu, was nicht von den anderen Fällen abgedeckt wird.
/* Beispiel 6 */
switch ($i) {
case 0:
print "i ist gleich 0";
break;
case 1:
print "i ist gleich 1";
break;
default:
print "i ist ungleich 0, 1";
}
Gibt man hinter einem break eine Zahl (int) größer Null an, wird versucht, diese Anzahl an Ebenen hinauf (hinaus) zu springen. Anwendung findet dies bei verschachtelten Schleifen, wie z.B. im folgenden:
$i = 0;
while($i < 10) {
$i++;
$j = 0;
while ($j < 10) {
$j += 2;
if ($i > $j)
break 2;
}
}
Das Beispiel stoppt mit den Werten 3 und 2 in $i und $j, weil $j in der inneren Schleife immer mindestens den Wert 2 hat.
Wenn man alle Einträge eines Arrays durchgehen will, nimmt man dazu meist eine for-Schleife. Handelt es sich um ein assoziatives Array oder spielt der Index keine Rolle bei der Auswertung der Daten, bietet sich eine alternative Schleife an, die sog. foreach-Schleife. Eine Gegenüberstellung der beiden zeigt, wie viel einfacher letztere zu handhaben ist:
$tage = array("Montag", "Dienstag", "Mittwoch",
"Donnerstag", "Freitag", "Samstag", "Sonntag");
// mit for
for ($i=0;$i<count($tage);$i++)
echo $tage[$i];
// mit foreach
foreach ($tage as $tag)
echo $tag;
Obiges Skript gibt nacheinander und ohne Leerzeichen oder Zeilenumbrüche zweimal alle Wochentage aus.
Wie man leicht sieht, weist man bei foreach nacheinander die Einträge eines Arrays (erste Variable) einer lokalen Variable zu, die in der Syntax hinter dem Schlüsselwort as angegeben wird. Bei jedem Schleifendurchlauf enthält diese lokale Variable eine Kopie (!) der Daten des jeweiligen Array-Eintrags; hierbei kann es sich z.B. auch wieder um ein Array handeln (wobei das eigentliche Array dann multidimensional wäre).
Besonders problematisch ist die erwähnte Kopiersemantik im Zusammenhang mit Objektreferenzen, siehe auch 20.2.1.3.
Zu beachten ist außerdem, daß foreach ein Array als ersten Eingabe erwartet, sonst gibt es eine Fehlermeldung. Um sicherzustellen, daß die Eingabe immer ein Array ist, kann man die Variable im Zweifelsfall initialisieren (auch auf Funktionen mit ähnlicher Problematik, wie z.B. in_array, anwendbar):
if (!isset($myArray)) $myArray = array(); foreach ($myArray as $key=>$val) echo "$key: $val\n";
Richtig interessant wird es aber erst mit der erweiterten Syntax, die es erlaubt, auch den Index (auch key, engl.: Schlüssel) des Arrays einer lokalen Variable zuzuweisen - das geht nämlich mit einer for-Schleife nicht so ohne weiteres:
$produkte = array("Auto"=>"22399",
"Fahrrad"=>"349", "Skates"=>"229");
$guthaben = 1325;
foreach ($produkte as $typ=>$preis) {
printf("%s: %s EUR\n", $typ,
number_format($preis, 2, ',', '.'));
if ($preis<=$guthaben) {
$guthaben -= $preis;
$gekauft[$typ] = true;
}
}
Die obige Funktion ,,kauft`` selbständig so lange Produkte, bis entweder die Liste durchlaufen ist - wie im Beispiel - oder das Guthaben nicht mehr reicht. Wenn man es nur an dieser Stelle verwendet, könnte man $produkte auch direkt als Eingabe für foreach hinschreiben, sich also die Variable ersparen. Im konkreten Fall liest sich die Ausgabe wie folgt:
Auto: 22.399,00 EUR Fahrrad: 349,00 EUR Skates: 229,00 EUR
Wenn man sich vorstellt, daß Arrays nicht nur statisch wie im Beispiel, sondern auch als Resultat einer Datenbank-Abfrage oder durch sonstige Berechnungen (z.B. POST-/GET-Übergabe) gefüllt werden können, macht der Zugriff auf den Index gleich mehr Sinn; bei komplexeren Arrays wird auch das Programmieren wesentlich übersichtlicher, wenn Namen statt Indizes benutzt werden, um mehrdimensionale Arrays zu strukturieren (vgl. auch mysql_fetch_array(): 10.1.6 und mysql_fetch_row(): 10.1.7).
$i = 10;
while ($i > 0) {
$i--;
if (!($i%2))
continue;
echo $i;
}
Die obige Schleife gibt genau die ungeraden Zahlen bis 10 aus, in absteigender Reihenfolge.
Optional kann hinter continue ein Integerwert angegeben werden, der analog zu break die Anzahl der ,,hinauszugehenden`` Ebenen angibt.
include("dateiname");
fügt an dieser Stelle den Inhalt der Datei `dateiname` ein. Dadurch ist es möglich,
Quellcode, der in mehreren Dateien benötigt wird, zentral zu halten, so daß Änderungen
einfacher werden.
Die Datei, die eingefügt wird, wird als HTML-Code interpretiert, deshalb muß, wenn in der Datei nur PHP-Code steht, diese Datei mit <?php anfangen und mit ?> aufhören (bzw. mit anderen PHP-Code-Markierungen, siehe Kapitel 8.2).
Wenn include() in Verbindung mit Bedingungen oder Schleifen eingesetzt wird, muß es immer in geschweiften Klammern geschrieben werden.
/* So ist es falsch */
if ($Bedingung)
include("Datei.inc");
/* So ist es richtig */
if ($Bedingung){
include("Datei.inc");
}
Bei PHP3 wird der require()-Ausdruck beim ersten Aufruf durch die Datei ersetzt. Wie bei include() wird erst einmal aus dem PHP-Modus gesprungen. Es gibt drei wesentliche Unterschiede zu include(): Zum einen wird require() immer ausgeführt, also auch dann, wenn es eigentlich abhängig von einer IF-Bedingung nicht ausgeführt werden dürfte; zum anderen wird es innerhalb einer Schleife (FOR, WHILE) nur ein einziges Mal ausgeführt - egal, wie oft die Schleife durchlaufen wird (trotzdem wird der Inhalt der eingefügten Datei mehrmals abgearbeitet). Der dritte Unterschied liegt in der Reaktion auf nicht vorhandene Dateien: include() gibt nur ein ,,Warning`` aus und PHP läuft weiter, bei require() bricht PHP mit einem ,,Fatal error:`` ab.
test.txt
Dies ist ein einfacher Text.<br> Die Variable i hat den Wert <?php echo $i; ?>.<br>
test1.txt
Datei test1.txt
test2.txt
Datei test2.txt
Aber jetzt zu den Beispielen:
echo "Erstmal ein einfaches include/require<br>\n";
$i = 5;
include("test.txt");
require("test.txt");
Die Ausgabe des Scripts ist, wie zu erwarten, folgende:
Erstmal ein einfaches include/require<br> Dies ist ein einfacher Text.<br> Die Variable i hat den Wert 5.<br> Dies ist ein einfacher Text.<br> Die Variable i hat den Wert 5.<br>
Auch in Schleifen können include() und require() verwendet werden.
echo "\nKleine for-Schleife fuer include<br>\n";
for ($i=1;$i<=3;$i++){
include("test.txt");
}
echo "\nKleine for-Schleife fuer require<br>\n";
for ($i=1;$i<=3;$i++){
require("test.txt");
}
Auch hier ist die Ausgabe, wie zu erwarten:
Kleine for-Schleife für include Dies ist ein einfacher Text. Die Variable i hat den Wert 1. Dies ist ein einfacher Text. Die Variable i hat den Wert 2. Dies ist ein einfacher Text. Die Variable i hat den Wert 3. Kleine for-Schleife für require Dies ist ein einfacher Text. Die Variable i hat den Wert 1. Dies ist ein einfacher Text. Die Variable i hat den Wert 2. Dies ist ein einfacher Text. Die Variable i hat den Wert 3.
Als letztes ein Beispiel, wo man einen Unterschied zwischen include() und require() sehen kann:
echo "\nKleine for-Schleife fuer include<br>\n";
for ($i=1;$i<=3;$i++){
include("test$i.txt");
}
echo "\nKleine for-Schleife fuer require<br>\n";
for ($i=1;$i<=3;$i++){
require("test$i.txt");
}
Hier gibt es einen Unterschied zwischen PHP3 und PHP4. Die Ausgabe bei PHP3 ist folgende:
Kleine for-Schleife für include<br> Datei test1.txt Datei test2.txt <br> <b>Warning</b>: Failed opening 'test3.txt' for inclusion in <b>.... Kleine for-Schleife für require<br> Datei test1.txt Datei test1.txt Datei test1.txt
Die Ausgabe von PHP4:
Kleine for-Schleife für include<br> Datei test1.txt Datei test2.txt <br> <b>Warning</b>: Failed opening 'test3.txt' for inclusion (include_.... Kleine for-Schleife für require<br> Datei test1.txt Datei test2.txt <br> <b>Fatal error</b>: Failed opening required 'test3.txt' (include_....
Die include()-Anweisung wird bei PHP3 und PHP4 identisch behandelt. In beiden Fällen wird versucht, die Dateien ,,test1.txt``,,,test2.txt`` und ,, test3.txt`` einzufügen, wobei letzteres mangels vorhandener Datei nicht funktioniert.
Bei require() sieht das ganze etwas anders aus. PHP3 verhält sich, wie ich es erwartet habe. Die Datei wird einmal eingefügt und dann wird der Inhalt der Datei mehrmals aufgerufen. Bei PHP4 verhält sich die require() wie die include() Anweisung.
Der Sinn ist einfach: Bei umfangreichen Webseiten gibt es häufig eine Datei, die die zentralen Funktionen enthält. Da diese in den Webseiten benötigt werden, fügt man sie immer am Anfang ein. Soweit kein Problem. Sobald aber mehrere zentrale Funktionsdateien existieren, die sich auch untereinander bedingen, wird es schwierig, weil jede nur einmal eingefügt werden darf.
Bei einigen Programmiersprachen findet eine Unterscheidung zwischen Funktionen statt, die einen Wert zurückgeben und solchen, die keinen Wert zurückgeben. Z.B. in Pascal/Delphi gibt es neben den sog. Funktionen, die einen Wert zurückgeben, sog. Prozeduren, die keinen Wert zurückgeben. PHP macht hier, genau wie C und C++, keinen Unterschied.
Die Syntax lautet wie folgt:
function foo($arg_1, $arg_2, ..., $arg_n) {
echo "Example function.\n";
return $retval;
}
Die Funktion bekommt die Argumente `Arg_1` bis `Arg_n` übergeben und gibt den Wert der Variablen `retval` zurück. Wird kein
`return` in der Funktion benutzt, hat man dasselbe Verhalten wie bei
einer Prozedur in Pascal/Delphi. Rückgabewerte müssen (im Gegensatz zu
Pascal/Delphi) nicht abgefragt werden.
Ein kleines Beispiel:
function my_sqr($num) { // gibt das Quadrat von $num zurueck
return $num * $num;
}
echo my_sqr(4); // gibt 16 aus
my_sqr(4); // ruft die Funktion auf,
// es passiert aber nichts
// (der Rueckgabewert wird ignoriert)
übergeben. Will man jedoch die Änderungen der Parameter in der Funktion auch in der
aufrufenden Funktion haben, muß man mit Variablenparameternbzw. Referenzparametern arbeiten.
Variablenparameter werden mit einem `&` im Funktionskopf gekennzeichnet.
Ein kleines Beispiel:
function foo1 ($st) {
$st .= ' und etwas mehr.';
// gleichbedeutend mit $st = $st.' und etwas mehr.';
}
function foo2 (&$st) {
$st .= ' und etwas mehr.';
}
$str = 'Dies ist ein String';
echo $str; //Ausgabe: Dies ist ein String
foo1 ($str);
echo $str; //Ausgabe: Dies ist ein String
foo2 ($str);
echo $str; //Ausgabe:
//Dies ist ein String und etwas mehr.
int printf (string format [, mixed args...])
Auf den ersten Blick mag das sehr verwirren und zur Frage führen, was daran denn einfacher sein soll. Bevor ich das beantworten kann, muß ich aber erst einmal vollständig erklären, was man mit printf() machen kann.
Im einfachsten Fall, wenn der zweite Parameterteil entfällt, verhält sich
printf() genauso wie print(). Anders jedoch, wenn mehr als
nur ein String übergeben wird: Dann spielt die Funktion ihre Stärken aus.
Im ersten Parameter, dem String, können nämlich Platzhalter eingebaut werden,
die durch das ersetzt werden, was hinter dem String in Form weiterer Argumente
angegeben wird. Im Normalfall gibt es also genau so viele zusätzliche
Argumente, wie Platzhalter in den String eingebaut wurden - der übrigens
auch vollständig in einer Variable enthalten sein kann.
Die genannten Platzhalter werden grundsätzlich mit einem Prozentzeichen
,%` eingeleitet, alles andere wird 1:1 ausgegeben - ausgenommen
natürlich Ausgabe-Formatierungszeichen wie \n. Will
man nun das Prozentzeichen selbst ausgeben, muß man es durch zwei Prozentzeichen
ausdrücken. Reines Ersetzen allein ist jedoch noch lange nicht alles,
was uns diese Funktion bietet. Vielmehr kann man mithilfe der Platzhalter
genau vorgeben, wie der Wert, der an entsprechender Stelle eingefügt wird,
formatiert werden soll. Hierbei reichen die Möglichkeiten von der Festlegung
auf einen bestimmten Typ wie Zahlen zu verschiedenen Basen bis hin zum
Zurechtschneiden, Ausrichten und Auffüllen von Daten.
Die beiden wichtigsten Platzhalter sind übrigens %s und %d. Während erstgenannter einen beliebigen String als Wert akzeptiert, wird bei letzterem der Wert als Integer interpretiert und als Dezimalzahl ausgegeben. Alle Werte, die kein Integer sind, werden kurzerhand in eine 0 verwandelt. Auf diese Weise kann man also sicher stellen, daß an einer bestimmten Stelle im auszugebenden String auch wirklich eine Zahl steht. Die Tabelle ,,Platzhalter`` listet alle erlaubten Platzhalter auf.
|
Zwischen dem einen Platzhalter einleitenden Prozentzeichen und dem Buchstaben, der die Typisierung des Platzhalters bestimmt, können noch weitere Angaben zur Formatierung gemacht werden. Diese sind allesamt optional und müssen, wenn sie angegeben werden, in folgender Reihenfolge auftreten:
Insgesamt ergibt sich somit folgende Syntax für Platzhalter:
%[Füllzeichen][Ausrichtung][Länge][Nachkommastellen]Typisierung
Im Allgemeinen braucht man die optionalen Angaben aber recht selten, so daß man dann ja immer noch mal nachlesen kann und es sich nicht wirklich merken muß.
Folgende Beispiele demonstrieren, wie sich das eben gelernte nun tatsächlich einsetzen läßt:
$tag = 13; $monat = 5; $jahr = 2009; $format = "%02d.%02d.%04d\n"; printf($format, $tag, $monat, $jahr); printf($format, 2*$tag, $monat, $jahr+2);
Gibt ,,13.05.2009`` und ein anderes wichtiges Datum aus.
$betrag1 = 12.95;
$betrag2 = 57.75;
$betrag = $betrag1 + $betrag2;
echo $betrag." ";
printf("%01.2f", $betrag);
Gibt ,,70.7 70.70`` aus.
Ist nun eine der Variablen für die Platzhalter im Formatierungs-String von anderen
abhängig, müßte normalerweise eine if-Abfrage vor dem Funktionsaufruf
getätigt werden. Ist diese Abfrage jedoch simpel, so kann man praktischerweise
auch die alternative Kurzvariante benutzen, die in Kapitel 8.2.14 vorgestellt
wurde. Um klar zu machen, daß es sich um eine solche handelt - und ggf. auch, um
Ergänzungen mittels des Punkt-Operators zu erlauben --, sollte man diese in runden Klammern schreiben.
Das folgende Beispiel gibt für die Zahlen von 0 bis 9 jeweils aus, ob sie gerade oder ungerade ist:
for ($i=0;$i<10;$i++)
printf("%d ist %sgerade.\n",
$i,
($i%2==0 ? "" : "un")
);
An dieser Stelle möchte ich die Gelegenheit nutzen, darauf hinzuweisen, daß die printf-Syntax nur dann als ,,guter Stil`` bezeichnet werden kann, wenn man sie auch sinnvoll einsetzt. Kommt z.B. eine einzelne Variable am Ende eines Strings vor, kann man sie einfach direkt mit dem Punktoperator anhängen und muß nicht gleich zu printf greifen. Ähnlich verhält es sich bei Variablen, die selbst vom Typ String sind und deren Name aus einem einzelnen Wort besteht. Dann kann man nämlich von der Eigenschaft der doppelt gequoteten Strings Gebrauch machen, daß Variablen in ihnen ersetzt werden.
Seit PHP-Version 4.06 kann man die Argumente (zur Erinnerung: das sind die zusätzlichen Parameter, deren Werte anstelle der Platzhalter ausgegeben werden) durchnumerieren und entsprechend referenzieren. Dadurch ergibt sich nicht nur die Möglichkeit, Argumente in der Reihenfolge ihres Auftretens bei der Ersetzung zu vertauschen, sondern auch bestimmte Argumente mehrfach zu plazieren, dabei jedoch ggf. verschieden zu formatieren. Eine Referenz auf ein Argument definiert man nun mittels folgender Syntax:
%[Argumentnummer\$][sonstige Formatierung]Typisierung
Folgendes Beispiel einer Sprach-angepaßten Datumsausgabe verdeutlicht die
Vorteile:
// Angenommen, in $lang stehe die Sprache
if ($lang == "de") {
$text = "Heute ist der %1\$d.%2\$d.%3\$04d.";
}
elseif ($lang == "en") {
$text = "Today's date is %3\$04d-%2\$02d-%1\$02d.";
}
else {
// unbekannte Sprache -> wir geben nur die Zahlen aus
$text = "%3\$04d-%2\$02d-%1\$02d";
}
$tag = 13;
$monat = 5;
$jahr = 2009;
// Ausgabe je nach Sprache:
// de -> Heute ist der 13.5.2009
// en -> Today's date is 2009-05-13
printf($text,$tag,$monat,$jahr);
Aber nocheinmal der Hinweis: Gerade durch die Möglichkeit des Numerierens kann die Komplexität des Codes schnell ansteigen (und das in wenigen Zeilen Code) und dadurch, ähnlich wie bei regulären Ausdrücken, die später noch behandelt werden, das Verständnis erheblich erschwert werden. Zugunsten der Lesbarkeit sollte man also auf allzu verspielte Konstruktionen verzichten und dann, wenn es doch einmal der Übersichtlichkeit dienen sollte, zumindest gut kommentieren.
Ein Beispiel für schlechten Stil wäre es demnach, schon beim Vorkommen eines einzelnen doppelten Arguments mit der Kanone Referenzierung auf den Spatz String zu schießen...
sprintf() läßt sich besonders gut im Zusammenhang mit SQL-Abfragen (siehe
auch nächstes Kapitel) besonders gut einsetzen, weil man damit den eigentlichen
Abfrage-String sauber von den Werten trennen kann, die in PHP-Variablen stecken.
Das Prinzip ist immer das gleiche: Der eigentlichen Abfragefunktion
mysql_query() übergibt man als einzigen Parameter das
sprintf()-Konstrukt, das den SQL-String zusammenbaut und zurückgibt
(der Empfänger ist, bedingt durch die Schachtelung, die Abfragefunktion).
Innerhalb dieses Konstruktes herrscht eine einfache Zweiteilung: der erste Parameter
definiert das String-Grundgerüst, also i.A. alle SQL-Befehle und Vergleichsoperatoren;
die restlichen Parameter geben die Quellen (Variablen) für die Werte an, die die im
String-Grundgerüst einzubauenden Platzhalter ersetzen. Für diese Variablen gilt
übrigens, daß man sie mittels addslashes() behandeln sollte, falls
ihre Werte möglicherweise Hochkommata enthalten könnten - diese werden durch
die erwähnte Funktion mittels Backslash escaped. Für die Rückwandlung bei der
Ausgabe an anderer Stelle steht die Funktion stripslashes() zur Verfügung,
die mit htmlentities() kombiniert gerade bei der HTML-Ausgabe
nützlich ist.
Eine schöne Aufgabe zum Gesagten findet sich in Kapitel 10.3.3.
Mit der Funktion number_format() bietet PHP die Möglichkeit, eine Zahl
zu formatieren. Insbesondere im Zusammenhang mit Internationalisierung läßt
sich diese Funktion nutzen, um Fließkommazahlen, die in PHP standardmäßig
bekanntlich entsprechend der amerikanischen Normen formatiert werden, anderen
Formaten entsprechend umzuwandeln, z.B. dem deutschen.
Die Syntax ist wie folgt, wobei wahlweise ein, zwei oder vier Parameter angegeben werden können (nicht drei!):
string number_format (float number [, int decimals
[, string dec_point , string thousands_sep]])
Wird nur die zu formatierende Zahl als einziger Parameter übergeben, so wird diese mit einem Komma (,) als Trennzeichen zwischen Tausenden und ohne Nachkommastellen ausgegeben.
Bei zwei Parametern wird die Zahl mit decimals Stellen hinter dem Komma ausgegeben. Auch hier trennt wieder ein Komma jede Tausenderstelle; die Nachkommastellen werden vom ganzzahligen Wert durch einen Punkt getrennt.
Die Ausgabe bei Angabe aller vier Parameter schließlich unterscheidet sich durch die bei nur zweien dadurch, daß sie die Zeichen für den Dezimaltrenner und das Tausender-Trennzeichen (in dieser Reihenfolge) verwendet.
Achtung: Es wird nur das erste Zeichen des Tausender-Trennzeichens für die Ausgabe benutzt!
Das Beispiel verdeutlicht, wofür diese Funktion vornehmlich benutzt werden kann:
function Euro ($preis) {
return sprintf("%s EUR\n",
number_format($preis, 2, ',', '.')
);
}
echo Euro(17392.48365); // Ausgabe: 17.392,48 EUR
Programmieren ist eine Sache. So zu programmieren, daß nicht nur man selbst, sondern auch andere den Code später in möglichst kurzer Zeit verstehen und daraufhin auch erweitern können, eine andere. Man darf auch nicht vergessen, daß es passieren kann, daß man selbst irgendwann mal - ein Jahr später oder so - noch etwas ändern will oder muß. Dabei ist es im Prinzip gar nicht so schwer: Das Ziel läßt sich erreichen, indem man strukturiert, kommentiert und abstrahiert (d.h. einen Codeabschnitt im Kontext betrachtet) sowie auf Wiederverwendbarkeit achtet. Für letzteres hat sich die objektorientierte Denkweise als hilfreich erwiesen und auch in PHP Einzug gehalten (siehe Kapitel 18). Selbst Kommentieren will gelernt sein - hier bietet sich PHPDOC (Kapitel 14) an.
Wenn es jedoch zur Struktur kommt, fragt sich mancher angesichts ellenlanger Codekonstrukte schnell, wie man dem beikommen soll. Da wird geschachtelt, was das Zeug hält, Zeichen werden wild escaped und Parameter derart in Strings eingebettet, daß selbst der Autor des Scripts sich nicht mehr an eine Änderung heranwagen möchte. Viele Autoren scheinen einfach nicht zu wissen, welch überaus hilfreiche und strukturierende Funktionen PHP von Hause aus bietet. Vielleicht tragen ja diese Zeilen dazu bei, daß sich das ändert - ich hoffe es jedenfalls.
Ähnlich wie in der Sprache C, von der PHP bekanntlich stark beeinflußt ist,
bietet unsere Scriptsprache die Funktionen printf() und sprintf().
Während printf() von print() abgeleitet ist, also letztlich
Text direkt ausgibt, dient sprintf() dazu, die Ausgabe der Funktion
als Argument (Parameter) einer weiteren Funktion oder einfach als Wert einer
Zuweisung zu benutzen.
. Beim
Syntax-Fehler kann der PHP-Interpreter nicht weiter arbeiten (weil er nicht
weiß, was er machen soll), bei der nicht initialisierte Variable hingegen
nimmt er einfach den Standardwert (und gibt im Normalfall keine Meldung aus).
An dieser Stelle kann jetzt ein Glaubenskrieg anfangen, ob es ein Fehler ist, von einer nicht initialisierten Variable zu lesen, oder nicht. Meiner Meinung nach ist es kein Fehler, aber wenn man es nicht erlaubt, schließt man einige Fehlerquellen.
<?php $variable1 = "Hallo Welt!"; // ganz viel Code echo $varaible1; ?>Frage: Was wird ausgegeben? Normalerweise nichts. Beim echo habe ich mich verschrieben und die Variable varaible1 ist nicht initialisiert, also leer. Normalerweise beginnt hier die große Suche.
Jetzt schalten wir (fast) alle Fehlermeldungen an.
<?php error_reporting(E_ALL); $variable1 = "Hallo Welt!"; // ganz viel Code echo $varaible1; ?>
Jetzt bekommen wir eine Warnung:
Notice: Undefined variable: varaible1 in [...]/test.php5 on line 8
Mit Hilfe von error_reporting kannst du PHP sagen, wie viele Fehlermeldungen du bekommen willst. Die genauen Stufen kannst du in der PHP-Dokumentation nachschlagen, ich zeige hier nur ein paar Beispiele:
// Fehlermeldungen ganz abschalten error_reporting(0); // Einfache Laufzeitfehler melden error_reporting(E_ERROR | E_WARNING | E_PARSE); // Alle Fehler ausser E_NOTICE melden // Dies ist die Standardeinstellung in php.ini error_reporting(E_ALL ^ E_NOTICE); // Alle PHP-Fehler melden // IMHO zum Entwickeln empfohlen error_reporting(E_ALL); // Seit PHP5 gibt es noch eine Steigerung error_reporting(E_ALL | E_STRICT);
Als Parameter nimmt man einfach die gewünschten Fehler und verknüpft sie mit einem bitweisen ODER.
Rekursion ist ein beliebtes Mittel der Programmierpraxis, um Probleme zu lösen, die an mindestens einer Stelle zu einem weiteren Problem führen, das aber in Wirklichkeit nichts anderes ist als das ursprüngliche Problem, ggf. mit leicht veränderten Voraussetzungen. Das klingt kompliziert, ist im Prinzip aber ganz einfach - wie das folgende beliebte Beispiel zeigt.
In der Mathematik gibt es den Begriff der Fakultät. Die Fakultät einer natürlichen Zahl
ist definiert als das Produkt aller Zahlen von 1 bis zu dieser Zahl, also z.B.
![]() . Mittels Rekursion kann man das wie folgt
ausdrücken:
. Mittels Rekursion kann man das wie folgt
ausdrücken:
![]() , d.h. die Fakultät von 1
wird definiert als 1 und für
, d.h. die Fakultät von 1
wird definiert als 1 und für ![]() ist die Fakultät von
ist die Fakultät von ![]() gleich
gleich ![]() mal der Fakultät
von
mal der Fakultät
von ![]() . Um das Ergebnis zu berechnen, muß man also erst die Fakultät von
. Um das Ergebnis zu berechnen, muß man also erst die Fakultät von ![]() berechnen. Diese ist aber definiert als
berechnen. Diese ist aber definiert als ![]() mal die Fakultät von
mal die Fakultät von
![]() usw. Irgendwann wird man dahin kommen, die Fakultät von
usw. Irgendwann wird man dahin kommen, die Fakultät von ![]() zu berechnen, wobei dieser
Ausdruck den Wert 1 haben wird. Dann ist es mit der Rekursion vorbei und die erste
Definition greift: Die Fakultät von 1 ist gleich 1. An dieser Stelle hat man also ein
erstes Teilergebnis, das mit all den
,,gemerkten`` Faktoren (der erste war
zu berechnen, wobei dieser
Ausdruck den Wert 1 haben wird. Dann ist es mit der Rekursion vorbei und die erste
Definition greift: Die Fakultät von 1 ist gleich 1. An dieser Stelle hat man also ein
erstes Teilergebnis, das mit all den
,,gemerkten`` Faktoren (der erste war ![]() ) multipliziert werden muß - man geht
also den ganzen ,,Weg`` wieder zurück und ,,sammelt`` dabei das auf, was
man ,,liegen gelassen`` hat. Am Ende hat man auf diese Weise die eigentliche
Fakultät berechnet. Das folgende kleine Beispiel sollte das Prinzip verdeutlichen:
) multipliziert werden muß - man geht
also den ganzen ,,Weg`` wieder zurück und ,,sammelt`` dabei das auf, was
man ,,liegen gelassen`` hat. Am Ende hat man auf diese Weise die eigentliche
Fakultät berechnet. Das folgende kleine Beispiel sollte das Prinzip verdeutlichen:
Die Frage, welchen Vorteil diese Methode gegenüber dem einfachen Zählen und Multiplizieren hat, läßt sich an diesem Beispiel noch nicht klären; mehr dazu später. Doch nun zu dem Paradebeispiel für Rekursion schlechthin:
Erschwert wird das Ganze dadurch, daß immer nur eine Scheibe gleichzeitig bewegt
werden und außerdem nie eine größere auf einer kleineren Scheibe liegen darf. Der
Legende nach geht die Welt unter, wenn die Mönche ihr Werk vollendet haben ...
Schnell wird klar, daß diese Aufgabe mit nur zwei Stapeln nicht lösbar ist: Ein dritter Stapel muß her. Mit diesen Vorgaben ist es nun möglich, die Aufgabe theoretisch für jede beliebige Anzahl von Scheiben zu lösen. Der zugehörige Algorithmus (das Problem wurde von einem Mathematiker definiert ...) lautet nun in Pseudo-Syntax:
Hanoi(n, Start, Temp, Ziel) {
Wenn n=0, dann Ende
Hanoi(n-1, Start, Ziel, Temp)
Bewege von Start nach Ziel
Hanoi(n-1, Temp, Start, Ziel)
}
Oder als normaler Text: Um einen Turm der Höhe n vom Start-Stapel auf den Ziel-Stapel zu bewegen, bewegt man erstmal einen Turm der Höhe n-1 (also alles bis auf die letzte Scheibe) auf einen Temp-Stapel, legt dann die letzte Scheibe auf den Ziel-Stapel und schichten danach den Turm vom Temp-Stapel auch noch auf den Ziel-Stapel.
Abgesehen davon, daß so eine Scheibe bei entsprechender Höhe des Stapels doch recht schwer werden dürfte (nach unten hin wird's ja immer größer!) gibt es noch ein Problem ganz anderer Natur: Das Umschichten der Stapel kostet Zeit. Gehen wir einmal gemeinsam den Algorithmus durch für drei Scheiben (vgl. Bild 8.1):
Man könnte meinen, daß das doch noch akzeptabel wäre. Das Problem wird aber schnell
deutlich, wenn man die Fälle vier, fünf oder sechs Scheiben durchspielt. Dabei ergibt sich
nämlich ein Aufwand von 15, 31 und 63 Schritten. Wer sich jetzt an eine gewisses
Schachbrett erinnert, der liegt richtig: Der Aufwand
wächst exponentiell mit der Anzahl der Scheiben. Genauer gesagt sind ![]() Schritte
notwendig, um
Schritte
notwendig, um ![]() Scheiben vom Start- auf den Zielstapel zu bewegen. Schon bei nur 20
Scheiben sind
Scheiben vom Start- auf den Zielstapel zu bewegen. Schon bei nur 20
Scheiben sind
![]() Schritte notwendig! Die Mönche wären also für hundert
Scheiben ihr Leben lang und darüber hinaus beschäftigt ...
Schritte notwendig! Die Mönche wären also für hundert
Scheiben ihr Leben lang und darüber hinaus beschäftigt ...
Doch was mag das nun mit Rekursion zu tun haben? Nun, wie man sich denken kann, machen die Mönche im Prinzip immer wieder dasselbe: Sie bewegen Scheiben von einem Stapel zum anderen. Das einzige, was sich dabei ändert, ist die jeweilige Ausgangssituation, d.h. es liegen jedesmal weniger Scheiben auf dem Startstapel und mehr auf dem Zielstapel. Sieht man sich nun einmal den Algorithmus näher an, sieht man, daß die Funktion sich selbst aufruft. Das mag auf den ersten Blick komisch aussehen, aber wenn man sicherstellt, daß die Funktion sich irgendwann nicht mehr aufruft, sondern statt dessen beendet, wird das Prinzip dahinter klar: Rekursion bedeutet, daß eine Funktion sich selbst eine bestimmte, zuvor meist nicht bekannte Anzahl mal selbst aufruft und nach etlichen Aufrufen irgendwann beendet. Damit ist dann zwar diese Funktion beendet, aber diese wurde ja von einer anderen Funktion aufgerufen, die nun an der Stelle nach dem Funktionsaufruf fortgesetzt wird. Das Besondere ist nun, daß beide Funktionen eigentlich gleich sind. Eigentlich deshalb, weil sie sich doch unterscheiden, und zwar nur in den Werten ihrer lokalen, selbstdefinierten Variablen und ggf. in der jeweiligen Stelle, wo die jeweilige Funktion fortgesetzt wird, wenn die von ihr aufgerufene Funktion sich beendet. Anstatt ,,jeweilige Funktion`` sagt man übrigens Rekursionsstufe, um zu verdeutlichen, daß es sich um einen wiederholten Aufruf derselben Funktion mit bestimmten Eingabedaten handelt.
Damit sind wir auch schon, ähnlich wie bei Schleifen, bei den beiden zentralen
Dingen, die ein Programmierer sicherstellen muß, wenn er Rekursion benutzt: Durch die
Anwendung der Rekursion muß sich die Situation derart ändern, daß in endlicher Zeit
(d.h. irgendwann einmal, in der Praxis natürlich je früher desto besser) der
Algorithmus für jede Aufgabenstellung terminiert, d.h. sinnvoll beendet wird - man
kann auch sagen, die Abbruchbedingung muß irgendwann erfüllt werden. Das Beispiel
der Türme von Hanoi zeigt
eindrucksvoll, daß rekursiv definierte Funktionen ein z.T. sehr hohes Wachstum auch
schon für niedrige Eingabewerte haben.
Die genannten Informationen werden intern auf dem sog. Stack verwaltet, auch Stapel
genannt. Von diesem kann man immer nur den obersten Eintrag sehen, der dem letzten
hinzugefügten Eintrag entspricht (das sog. LIFO-Prinzip).
Die Größe des Stacks ist außerdem beschränkt, da er sich ja den Hauptspeicher mit dem
Programm selbst sowie seinen Daten teilen muß, im Gegensatz zu diesen Speicherbereichen aber
i.A. vom Speicherende her wächst.
. Verwendet man beispielsweise eine Variable
Nur der Vollständigkeit halber gebe ich hier doch nochmal die genannte Ackermann-Funktion an:
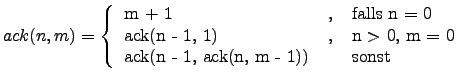
Die Formel liest sich dabei wie folgt: Der Ackermann-Wert zweier natürlicher Zahlen
![]() und
und ![]() ist
ist ![]() , falls
, falls ![]() Null ist. Ist dagegen
Null ist. Ist dagegen ![]() größer Null und gleichzeitig
größer Null und gleichzeitig
![]() gleich Null, so berechnet sich das Ergebnis rekursiv mit
gleich Null, so berechnet sich das Ergebnis rekursiv mit ![]() und
und ![]() .
In jedem anderen Fall, also letztlich nur wenn
.
In jedem anderen Fall, also letztlich nur wenn ![]() und
und ![]() größer Null sind, muß zuerst
die Rekursion mit
größer Null sind, muß zuerst
die Rekursion mit ![]() und
und ![]() berechnet werden und das Ergebnis als
berechnet werden und das Ergebnis als
![]() für die Rekursion mit
für die Rekursion mit ![]() eingesetzt werden.
eingesetzt werden.
Beispiel: ![]() .
.
Angenommen, du möchtest ein Webmail-System bauen. Die PHP-IMAP-Funktionen
bieten schon recht viel dessen, was man für das Backend braucht, aber an
einer zentralen Stelle muß man doch selbst etwas konstruieren: Dann nämlich,
wenn es darum geht, E-Mails zu entschlüsseln. Da eine E-Mail in Wirklichkeit
nichts anderes als ein speziell gegliederter ASCII-Text ist, kann man das
Erkennen von Attachments (Mail-Anhängen) oder anderen speziellen Teilen,
wie z.B. dem HTML-Anteil einer Mail, auf das Erkennen von bestimmten
Strings zurückführen. Grundsätzlich enthält eine ,,moderne`` Mail
oft mehrere Teile, MIME-Parts genannt. Diese Parts sind
in einem Baum (siehe auch Kapitel 7.4) organisiert, der sich
beliebig verzweigen kann. Durch diesen Aufbau ist es z.B. möglich, eine
E-Mail mit Attachments weiterzuleiten, dabei neue Attachments anzuhängen und
trotzdem die Ursprungsmail mit ihren Attachments theoretisch problemlos
extrahieren zu können. Wenn du diesen Satz in seiner ganzen Komplexität genau
gelesen hast, hast du es vielleicht schon gemerkt: Sowohl das Anlegen wie auch
das Auslesen bzw. Interpretieren eines solchen Baumes läßt sich am besten
rekursiv lösen. Ein iterativer Ansatz ist bestimmt auch möglich, aber sicher
sehr viel weniger intuitiv, als einfach Rekursion zu benutzen.
Benutzt man nun tatsächlich die PHP-IMAP-Funktionen, dann wird man schnell feststellen, daß die für das Extrahieren bestimmter Parts nötige Funktion imap_fetchbody() einen String als Parameter erwartet, der einen Part identifiziert. Dieser String setzt sich aus durch Punkte getrennten Zahlen zusammen und muß leider - wie oben schon angedeutet - selbst zusammengezimmert werden. Hierzu bietet es sich an, die Funktion imap_fetchstructure() zu benutzen, um die Struktur für die jeweilige E-Mail zu bekommen (in diesem Fall in Form eines verschachtelten Objekts).
Der eigentlichen, rekursiv definierten, neu zu schreibenden Funktion übergibt man nun das Parts-Objekt, das imap_fetchstructure() als Unterobjekt der Hauptstruktur zurückliefert. Die rekursive Funktion geht nun durch den kompletten Parts-Baum und stellt für jedes Blatt den Part-Typ fest. Im Falle eines Attachments wird einfach dessen Struktur analysiert und die relevanten Daten wie Name und Kodierung vermerkt. Handelt es sich jedoch um einen anzuzeigenden Text-Part, wird dieser an den String angehängt, der später als Nachrichtentext ausgegeben wird. Zur Extraktion des Textes aus einem solchen Part muß wie gesagt der spezielle Identifizierungsstring bekannt sein. Diesen String erhält man wie folgt:
Der folgend dargestellte Aufbau einer komplexen Mail sollte das verdeutlichen (übersetzte Version von http://www.ietf.org/rfc/rfc2060.txt):
HEADER ([RFC-822] Header der Nachricht) TEXT MULTIPART/MIXED 1 TEXT/PLAIN 2 APPLICATION/OCTET-STREAM 3 MESSAGE/RFC822 3.HEADER ([RFC-822] Header der Nachricht) 3.TEXT ([RFC-822] Textkörper der Nachricht) 3.1 TEXT/PLAIN 3.2 APPLICATION/OCTET-STREAM 4 MULTIPART/MIXED 4.1 IMAGE/GIF 4.1.MIME ([MIME-IMB] Header des IMAGE/GIF) 4.2 MESSAGE/RFC822 4.2.HEADER ([RFC-822] Header der Nachricht) 4.2.TEXT ([RFC-822] Textkörper der Nachricht) 4.2.1 TEXT/PLAIN 4.2.2 MULTIPART/ALTERNATIVE 4.2.2.1 TEXT/PLAIN 4.2.2.2 TEXT/RICHTEXT
Solch komplexe Mails können z.B. dann entstehen, wenn man eine Nachricht, die bereits Attachments enthält, komplett eingebettet weiterleitet und dann noch eigene Attachments anhängt. Außerdem werden auch HTML-Mails intern mit MIME-Parts realisiert, da sie neben dem HTML-Teil meist auch einen reinen ASCII-Textteil enthalten.
Das folgende Code-Beispiel zeigt den Rahmen einer entsprechenden Implementierung innerhalb einer geeigneten Klasse (siehe Kapitel 20), die bereits einen Mailbox-Stream und die Message-ID bereitstellt. Die Funktion imap_fetchbody extrahiert hierbei den Nachrichtenkörper, also den eigentlichen Text. Sie erwartet als Parameter einen geöffneten Mailbox-Stream, eine Message-ID, eine Part-ID sowie (optional) ein Flag zum Benutzen von eindeutigen Message-IDs. Auf ihren Rückgabewert werden dann noch einmal einige Funktionen angewendet, um Leerzeichen vorne und hinten sowie Escapezeichen zu entfernen sowie Sonderzeichen (Umlaute, ...) zu konvertieren. Die Funktion imap_fetchstructure schließlich liefert ein Objekt zurück, das Aufschluß über die Struktur der E-Mail gibt und u.a. alle MIME-Parts in verschachtelten Arrays enthält.
function parseParts($parts, $data) {
// Schleife über alle Parts der aktuellen Ebene
for ($i=0;$i<count($parts);$i++) {
// ID-String: <ID-String>.<Partnummer>
$idstr = sprintf("%s%s%d", $data["idstr"],
($data["idstr"]!='' ? '.' : ''), $i+1);
if (is_array($parts[$i]->parts)) {
// Rekursion, falls aktueller Part Unterparts enthält
$tmp = $data["idstr"];
$data["idstr"] = $idstr;
$data = $this->parseParts($parts[$i]->parts, $data);
$data["idstr"] = $tmp;
}
... // Code für Attachment-Erkennung
if (!$is_attachment) {
// kein Attachment -> Body
$msgbody = htmlspecialchars(stripslashes(trim(
imap_fetchbody($this->mbox, $this->msgid,
$idstr, FT_UID))));
... // weitere Behandlung
}
}
return $data;
}
$structure = imap_fetchstructure($this->mbox,
$this->msgid, FT_UID);
$data = $this->parseParts($structure->parts, $data);
... // Daten-Auswertung
In diesem Beispiel ist die Abbruchbedingung in Form der return-Anweisung noch recht einfach erkennbar. Wichtig ist dabei weniger, daß es eine Anweisung zur Beendigung von Rekursionsstufen gibt, sondern vielmehr, daß eine solche Anweisung im Verlauf der Rekursion immer in endlicher Zeit erreicht werden muß. Andernfalls gibt es schnell eine sich unendlich weiterverschachtelnde Rekursion: das Pendant zur Endlosschleife. Da bei einer Rekursion rechnerintern die Rücksprungadressen immer auf dem Stack gespeichert werden (s.o.) und dieser irgendwann den normalen Speicher überschreiben würde, gibt es dann mehr oder weniger schnell den gefürchteten stack overflow, d.h. der Rechner riegelt ab, bevor schlimmeres passiert. Da PHP nur eine Scriptsprache ist, wird aber schlimmstenfalls nur das Script unsanft beendet. Vermeiden sollte man sowas aber trotzdem auf jeden Fall!
![]()
![]()
![]()
![]()
![]()
Up: Einführung PHP
Previous: Einführung PHP
Next: PHP & HTML
![\includegraphics[height=20cm]{images/hanoi}](img43.png)