![]()
![]()
![]()
![]()
![]()
![]() Previous: Datenbanksystem
Up: Theoretische Grundlagen
Next: Praktischer Teil SQL
Previous: Datenbanksystem
Up: Theoretische Grundlagen
Next: Praktischer Teil SQL
![]()
![]()
![]()
![]()
![]()
![]() Previous: Datenbanksystem
Up: Theoretische Grundlagen
Next: Praktischer Teil SQL
Previous: Datenbanksystem
Up: Theoretische Grundlagen
Next: Praktischer Teil SQL
Man sollte sich für diesen Schritt ruhig ein wenig Zeit nehmen, weil es nachher häufig unmöglich ist, ohne großen Aufwand Fehler zu beheben.
| Vor-/Nachname | Vorname | Straße |
|---|---|---|
| Hans Maier | Hans | Musterstr. 5 |
| Jürgen Müller | Jürgen | In dem Muster 4 |
| Christof Meier | Christof | Gibt es nicht 1 |
Wie man leicht erkennen kann, kommt der jeweilige Vorname in zwei Spalten vor. Dies bringt zwei Nachteile mit sich: Zum einen kostet es mehr Speicherplatz, was bei einigen 1000 Datensätzen schon etwas ausmacht; zum anderen werden Änderungen schwieriger, anfälliger für Fehler und auch aufwendiger, da ja zwei Attribute geändert werden müssen. Wenn dies nicht erfolgt, treten Inkonsistenzen auf.
Wenn zum Beispiel Christof Meier feststellt, daß ein Christoph, mit `f` geschrieben, einfach nicht so gut aussieht und er es gerne in Christoph geändert haben würde, dabei aber nur das Attribut Vorname geändert wird, könnten zum Beispiel die Briefe weiter an Christof Meier geschickt werden, weil hier das Attribut Vor-/Nachname verwendet wird. An einer anderen Stelle im Programm würde aber wieder der korrigierte Christoph auftauchen.
Das DBMS verfügt nicht über einen definierten Zugriffsweg auf einen bestimmten Datensatz. Deshalb muß in jeder Zeile einer Tabelle ein Wert enthalten sein, der diesen Eintrag eindeutig kennzeichnet bzw. identifiziert. Um die Eindeutigkeit der Tabellenzeilen zu gewährleisten, erweitert man den Datensatz um ein Identifikationsmerkmal, z.B. wird einem Artikeldatensatz eine Artikelnummer zugeordnet. Dieses Merkmal nennt man Schlüssel.
Beim Festlegen des Schlüssels kann man einen Schlüssel selbst definieren oder einen fremddefinierten übernehmen. Bei einem Buch würde sich da die ISBN-Nummer anbieten. Um nicht Gefahr zu laufen, daß durch eine Änderung solcher fremddefinierten Schlüssel im DBS Inkonsistenzen auftreten, zum Beispiel, weil der Schlüssel nicht mehr eindeutig ist, empfiehlt es sich häufig, einen eigenen zu nehmen.
Andererseits kann man sich auch zuerst überlegen, welche Daten überhaupt anfallen und
wie diese am besten organisiert werden. Anschließend kann man sich dazu die entsprechenden
Funktionen ausdenken. Da Datenbanken in der Regel zum Speichern von Daten gedacht sind, empfiehlt
sich letztere Vorgehensweise; man sollte aber trotzdem die benötigten Funktionen nicht aus
dem Auge verlieren. Also zusammenfassend:
Als erstes muß man feststellen, welche Daten gebraucht werden bzw. anfallen und wie diese
organisiert werden sollen. Im nächsten Schritt ist zu überlegen, ob alle Anforderungen
realisierbar sind.
Um die benötigten Tabellen zu entwickeln, gibt es für einfache DBs im Prinzip zwei Möglichkeiten: Entweder stur nach Schema-F über die fünf Normalformen (Kapitel 4.4) oder etwas intuitiver über das ER-Modell (Kapitel 4.6), evtl. anschließend mit Kontrolle durch die fünf Normalformen (Kapitel 4.4).
Erst wenn man größere DBs entwickelt, muß man mit beiden Möglichkeiten gleichzeitig arbeiten. Das heißt, erst mit dem ER-Modell eine Grundstruktur festlegen und diese dann mit den fünf Normalformen überprüfen.
Die Normalformen sind ein Regelwerk, mit deren Hilfe man überprüfen kann, ob sich ein Datenmodell sauber mit Hilfe eines Relationalen DBMS implementieren läßt. Man spricht auch von Normalisierung.
Definition:
Ein Relationstyp ist in der 1. Normalform, wenn alle Attribute maximal einen Wert haben. Am Kreuzungspunkt einer Spalte mit einer Reihe darf also maximal ein Datenwert stehen. Das Nichtvorhandensein von Daten ist zulässig.
Mit anderen Worten: Wiederholungsgruppen sind nicht erlaubt. [3]Ein kleines Beispiel:
| Auftrag | ||||
| AuftragNr | Datum | KundenNr | ArtikelNr | Anzahl |
|---|---|---|---|---|
| 4711 | 03.10.1999 | 12345 | 4692 | 5 |
| 0567 | 2 | |||
| 5671 | 3 | |||
| 0579 | 1 | |||
| 0815 | 01.03.1998 | 54321 | 8971 | 2 |
| 5324 | 5 | |||
| 0579 | 9 | |||
Um die Wiederholungsgruppe![[*]](footnote.png) zu
vermeiden, wird die Relation `Auftrag` in zwei gesonderte Relationen
aufgespalten. Dadurch würden sich die folgenden beiden Tabellen ergeben:
zu
vermeiden, wird die Relation `Auftrag` in zwei gesonderte Relationen
aufgespalten. Dadurch würden sich die folgenden beiden Tabellen ergeben:
| best. Artikel | |
| ArtikelNr | Anzahl |
|---|---|
| 4692 | 5 |
| 0567 | 2 |
| 5671 | 3 |
| 0579 | 1 |
| 8971 | 2 |
| 5324 | 5 |
| 0579 | 9 |
| Auftrag | ||
| AuftragNr | Datum | KundenNr |
|---|---|---|
| 4711 | 3.10.1999 | 12345 |
| 0815 | 1.3.1998 | 54321 |
Dieses Problem ist einfach zu lösen: Wir müssen nur festhalten, welche Artikel zu welcher
Bestellung gehören. Da die AuftragNr eindeutig ist, nehmen wir diese als
Primärschlüssel für `Auftrag`. Nun fügen wir noch dieser Spalte entsprechend
ihrer Werte der Relation `best. Artikel` hinzu, und schon haben wir wieder unsere
Zuordnung.
In dieser Konstellation wird die Spalte `AuftragNr` in `best. Artikel` als Fremdschlüssel bezeichnet.
Weiterhin wurde schon auf Seite ![[*]](crossref.png) gefordert, daß jede Zeile eindeutig
ansprechbar sein muß. Wie aber ist das in unserem Fall der bestellten Artikel zu erreichen?
gefordert, daß jede Zeile eindeutig
ansprechbar sein muß. Wie aber ist das in unserem Fall der bestellten Artikel zu erreichen?
Nun, die AuftragNr und die ArtikelNr kommen zwar mehrfach vor, trotzdem ist die Lösung
aber ganz einfach: Die Kombination aus AuftragNr und ArtikelNr muß eindeutig sein. Wenn
wir also diese Kombination wählen, ist die o.g. Forderung erfüllt. Diese Kombination wird
übrigens als ,zusammengesetzter Primärschlüssel`
bezeichnet.
Damit ergeben sich für unser Beispiel die folgenden beiden Relationen:
| best. Artikel | ||
| # AufragNr | # ArtikelNr | Anzahl |
|---|---|---|
| 4711 | 4692 | 5 |
| 4711 | 0567 | 2 |
| 4711 | 5671 | 3 |
| 4711 | 0579 | 1 |
| 0815 | 8971 | 2 |
| 0815 | 5324 | 5 |
| 0815 | 0579 | 9 |
| Auftrag | ||
| # AuftragNr | Datum | KundenNr |
|---|---|---|
| 4711 | 3.10.1999 | 12345 |
| 0815 | 1.3.1998 | 54321 |
Definition:
Ein Relationstyp ist in der 2. Normalform, wenn er in der 1. Normalform ist und jedes Attribut vom gesamten Primärschlüssel abhängt.
Relationstypen, die in der 1. Normalform sind, sind automatisch in der 2. Normalform, wenn ihr Primärschlüssel nicht zusammengesetzt ist. [3]Ein kleines Beispiel:
| best. Artikel | |||
| # AuftragNr | # ArtikelNr | Menge | Hersteller |
|---|---|---|---|
| 4711 | 4692 | 5 | Blech-AG |
| 4711 | 0567 | 2 | Keramik GmbH |
| 4711 | 5671 | 3 | Baustoff KG |
| 4711 | 0579 | 1 | Keramik GmbH |
| 0815 | 8971 | 2 | Keramik GmbH |
| 0815 | 5324 | 5 | Baustoff KG |
| 0815 | 0579 | 9 | Keramik GmbH |
In diesem Beispiel ist das Attribut `Hersteller` nur vom Teilschlüssel ` ArtikelNr` und nicht auch von `AuftragNr` abhängig. Damit die Relation der 2. NF genügt, muß das Attribut `Hersteller` aus der Relation herausgenommen und der (neuen) Relation Artikel zugeordnet werden.
Daraus würden dann die folgenden zwei Relationen entstehen:
| best. Artikel | ||
| # AufragNr | # ArtikelNr | Anzahl |
|---|---|---|
| 4711 | 4692 | 5 |
| 4711 | 0567 | 2 |
| 4711 | 5671 | 3 |
| 4711 | 0579 | 1 |
| 0815 | 8971 | 2 |
| 0815 | 5324 | 5 |
| 0815 | 0579 | 9 |
| Artikel | |
| # ArtikelNr | Hersteller |
|---|---|
| 4692 | Blech-AG |
| 0537 | Keramik GmbH |
| 5671 | Baustoff KG |
| 0579 | Keramik GmbH |
| 8971 | Keramik GmbH |
| 5324 | Keramik GmbH |
Definition:
Die 3. Normalform ist erfüllt, wenn die 2. Normalform erfüllt ist und die Nicht-Schlüssel-Attribute funktional unabhängig voneinander sind.
Sind A und B Attribute eines Relationstyps, so ist B funktional abhängig von A, wenn für jedes Vorkommen ein und desselben Wertes von A immer derselbe Wert von B auftreten muß.
Eine funktionale Abhängigkeit kann auch von einer Gruppe von Attributen bestehen. [3]Ein kleines Beispiel:
| Artikel | |||
| # ArtikelNr | Bezeichnung | HerstellerNr | Hersteller |
|---|---|---|---|
| 4692 | Putzeimer | 5410 | Blech-AG |
| 0567 | Waschbecken | 5647 | Keramik GmbH |
| 5671 | Gummi | 6740 | Baustoff KG |
| 0579 | Teller | 5647 | Keramik GmbH |
| 8971 | Tasse | 5647 | Keramik GmbH |
| 5324 | Badewanne | 5647 | Keramik GmbH |
Wie man unschwer erkennen kann, ist der Herstellername von der ArtikelNr über die HerstellerNr transitiv abhängig. Oder anders ausgedrückt: Der Herstellername ist funktional abhängig von der HerstellerNr, die wiederum abhängig von der ArtikelNr ist. Und diese funktionale Abhängigkeit der beiden Nicht-Schlüssel-Attribute HerstellerNr und Hersteller ist nicht erlaubt.
Was jetzt kommt, ist nicht schwer zu erraten: Die Tabelle `Artikel` wird in die beiden Tabellen `Artikel` und `Hersteller` aufgespalten. Das heißt, es ergeben sich folgende Tabellen:
| Artikel | ||
| # ArtikelNr | Bezeichnung | HerstellerNr |
|---|---|---|
| 4692 | Putzeimer | 5410 |
| 0567 | Waschbecken | 5647 |
| 5671 | Gummi | 6740 |
| 0579 | Teller | 5647 |
| 8971 | Tasse | 5647 |
| 5324 | Badewanne | 5647 |
| Hersteller | |
| # HerstellerNr | Hersteller |
|---|---|
| 5410 | Blech-AG |
| 5647 | Keramik GmbH |
| 6740 | Baustoff KG |
Definition:
Die 4. Normalform ist erfüllt, wenn die 3. Normalform erfüllt ist und wenn keine paarweise auftretenden mehrwertigen Abhängigkeiten vorhanden sind.
Sind A, B und C Attribute eines Relationstypes, so ist C mehrwertig abhängig von A, falls für jeden Wert von A für alle Werte von B, die zusammen mit diesem Wert von A auftreten, jeweils die gleiche Wertemenge von C auftreten muß. Für verschiedene Werte von A können unterschiedliche Wertemengen von C auftreten.
Bei Verstoß gegen die 4. Normalform können ,,Gruppeninkonsistenzen`` auftreten. [3]Kurzes Beispiel:
| Disposition | ||
| ArtikelNr | Lager | AuftragNr |
|---|---|---|
| 04532 | SFO-4 | 2063 |
| 04532 | NYC-4 | 2063 |
| 04532 | SFO-4 | 2267 |
| 04532 | NYC-4 | 2267 |
| 53944 | ORD-1 | 2088 |
| 53944 | SFO-1 | 2088 |
| 53944 | LAX-1 | 2088 |
| 53944 | ORD-1 | 2070 |
| 53944 | SFO-1 | 2070 |
| 53944 | LAX-1 | 2070 |
In der Relation Disposition sind folgende Informationen festgehalten:
Es soll nicht ausgesagt werden, aus welchem Lager der Artikel für einen Auftrag kommt.
Folgende mehrwertige Abhängigkeiten liegen vor:
Für jeden Artikel muß für alle Aufträge, für die der Artikel bestellt ist, jeweils die gleiche Gruppe von Lagern auftreten.
Für jeden Artikel muß für alle Lager, in denen der Artikel aufbewahrt wird, jeweils die gleiche Gruppe von Aufträgen auftreten.
Damit die Relation der 4. NF genügt, muß sie in zwei neue Relationen (Artikel-Lager und Artikel-Auftrag) aufgespalten werden. Die erste Relation beschreibt, in welchem Zusammenhang Artikel und Lager stehen; die zweite den Zusammenhang zwischen Artikel und Auftrag.
Definition:
Ein Relationstyp ist in der 5. Normalform, wenn er in der 4. Normalform ist und er sich unter keinen Umständen durch Kombination einfacherer Relationstypen mit unterschiedlichen Schlüsseln bilden läßt. [3]
Das ist doch eigentlich selbsterklärend, oder? ;-)
Bei umfangreichen Datenbeständen mit hohen Zugriffszahlen kann es sich jedoch teilweise
empfehlen, aus Performancegründen wieder eine gewisse Denormalisierung herzustellen. Da
wir aber keine so hohen Zugriffszahlen und Datenbestände haben, daß der Server überlastet
werden könnte, können wir diesen Schritt getrost übergehen.
Hierbei kann man sagen, daß es weniger problematisch ist, mit sich nicht ändernden Daten
gegen die Normalformen zu verstoßen. Bei diesen entfällt nämlich das Problem, daß beim
Ändern nicht alle Daten verändert werden und dadurch Widersprüche entstehen. Trotzdem
sollte man sich immer im klaren darüber sein, wann man gegen die Normalformen verstoßen
hat!
Als nächstes ist anhand des Streifendiagramms (Kapitel 4.5) zu überprüfen, ob die Tabellen den Anforderungen der Vorgänge entsprechen.
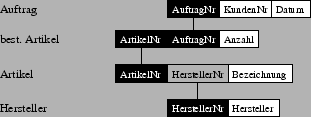
Als Beispiel habe ich die Relationen `Auftrag`, `best. Artikel`, ` Artikel` und `Hersteller` aus dem obigen Beispiel in der Abbildung 4.1 dargestellt.
Es gibt verschiedene Formen, das ER-Modell zu zeichnen. Ich benutze hier das sogenannte Krähenfuß-Diagramm.
Was bedeutet eigentlich Entity-Relationship ??
Für Entität gibt es verschiedene gebräuchliche Definitionen:
Entität [mlat.]die, -/-en, Philosophie: die bestimmte Seinsverfassung (Wesen) des einzelnen Seienden, auch diese selbst. [1]
Entität [lat.-mlat.] die, -, -en: 1. Dasein im Unterschied zum Wesen eines Dinges (Philos.). 2. [gegebene] Größe [2]Wer jetzt weiß, was Entity bedeutet, kann diesen Absatz überspringen; für alle anderen versuche ich, es anders zu erklären: ,,Entity`` kann man mit ,,Objekt`` oder ,,Ding`` ins Deutsche übersetzen, letztlich sind es konkrete Objekte der Realität. Beim ER-Modell sind Entities Objekte, die über Attribute weiter beschrieben werden können.
Nachdem wir jetzt hoffentlich wissen, was Entity bedeutet, sind wir beim zweiten Begriff angelangt: Relationship bedeutet so viel wie ,,Beziehung`` oder ,, Relation``.
Ein kleines Beispiel:
Für ein Unternehmen soll eine Datenbank entwickelt werden. Es sollen alle Mitarbeiter der Firma gespeichert werden. Jeder Mitarbeiter hat einen Vorgesetzten und gehört zu einer Abteilung. Außerdem verfügt jede Abteilung über einige oder keine PKWs aus dem Fuhrpark für die Mitarbeiter. Zusätzlich soll die Antwort auf die Frage möglich sein, wer wann mit welchem Wagen wie viele Kilometer gefahren ist.
Diese Realtitätsbeschreibung legt drei Entitäten nahe: Mitarbeiter, Abteilung, PKW. Die Zeichnung 4.2 stellt die Beziehung der drei Entitäten und deren Attribute dar.
Wie man unschwer erkennen kann, stellen die Rechtecke die Entitäten da. Sowohl die Entitäten, als auch nachher die Tabellen werden grundsätzlich in der Einzahl bezeichnet.
Die Striche zwischen den Entitäten stellen deren Beziehung da. Der durchgezogene Strich bedeutet genau einer, der gestrichelte einer oder keiner. Der Krähenfuß auf der anderen Seite bedeutet einer oder mehrere. Die Wörter an den Strichen zeigen, was die Beziehung aussagt.
Also z.B.: Ein Mitarbeiter gehört zu genau einer Abteilung. Eine Abteilung kann aus keinem, einem oder mehreren Mitarbeiter bestehen. Daß eine Abteilung keinen Mitarbeiter haben kann, mag auf den ersten Blick merkwürdig erscheinen. Was ist aber, wenn die Abteilung gerade erst eingerichtet wurde?
Wie wir bei der Entität Mitarbeiter sehen, kann es durchaus auch eine Beziehung zwischen einer Entität mit sich selber geben. Über diese Beziehung wird ausgesagt wer Vorgesetzter von wem ist. Daß diese Beziehung von beider Seite eine ,kann`-Beziehung sein soll, mag auf den ersten Blick komisch erscheinen. Aber nicht jeder Mitarbeiter hat einen Vorgesetzten, der Chef hat keinen.
In den Rechtecken stehen die wichtigsten Attribute. Primärschlüssel werden durch ein # gekennzeichnet, Primärschlüsselkandidaten dagegen durch (#) markiert. Attribute, bei denen ein Wert eingetragen werden muß, werden mit einem * versehen; bei den optionalen wird ein o verwendet.
Wenn man sich dieses ER-Modell einmal genauer ansieht, stellt man fest, daß es gegen die 1. NF verstößt. Die Beziehung zwischen `Mitarbeiter` und `PKW` ist eine n:m Beziehung. Um dieses Problem zu lösen, wird eine sog. Link-Relation erstellt. Wie das dann genau aussieht, ist in Abbildung 4.3 dargestellt.
| Tabelle | Primärschlüssel |
|---|---|
| Mitarbeiter | MNr |
| Abteilung | AbtNr |
| Fahrtenbuch | MNr, PKWNr, Datum |
| PKW | PKWNr |
Die Relation `Fahrtenbuch` hat einen zusammengesetzten Primärschlüssel. Die ` MNr` oder auch das Datum für sich alleine wären nicht eindeutig, da ein Mitarbeiter ja nicht nur einmal Auto fährt und zu einem Zeitpunkt ja auch ggf. mehrere Leute gleichzeitig Autos fahren. In der Kombination jedoch sind die drei Attribute eindeutig.
Bei `PKW` wurde nicht das Kennzeichen als Primärschlüssel genommen, obwohl es sich dafür eignen würde (mit Sicherheit eindeutig). Allerdings kann es passieren, daß ein PKW ein neues Kennzeichen bekommt. Um auch dann noch die Datenintegrität sicherstellen zu können, habe ich ein neues Attribut eingeführt.
Nachdem man die Primärschlüssel herausgesucht hat, müssen auch die Fremdschlüssel gesucht werden, damit man die Beziehung zwischen den Relationen herstellen kann. Das ist mit dem Krähenfußdiagramm relativ einfach. Alle Relationen, die einen Krähenfuß haben, bekommen den Primärschlüssel der anderen Relation. D.h. es muß z.B. die Abteilungsnummer in die Relation `Mitarbeiter` eingefügt werden. Das ist auch logisch, denn eine Abteilung kann natürlich auch mehrere Mitarbeiter haben. Würde man dagegen die Mitarbeiter-Nummer in `Abteilung` einfügen, hätte man einen Verstoß gegen die 1. NF.
Aus unserem Beispiel ergäben sich also folgende Relationen (mit Angabe der zu den
Fremdschlüsseln gehörigen Primärschlüssel):
| Tabelle | Primärschlüssel | Fremdschlüssel |
|---|---|---|
| Mitarbeiter | MNr | AbtNr [Abteilung(AbtNr)] |
| VNr [Mitarbeiter(MNr)] | ||
| Abteilung | AbtNr | |
| Fahrtenbuch | MNr, PKWNr, Datum | MNr [Mitarbeiter(MNr)] |
| PKWNr [PKW(PKWNr)] | ||
| PKW | PKWNr | AbtNr [Abteilung(AbtNr)] |
Als letztes müssen noch die benötigten Attribute den Relationen hinzugefügt und für alle Attribute die entsprechenden Datentypen festgelegt werden.
Bei der Überlegung, welcher Datentyp zu verwenden ist, sollte man nicht vom Normalfall ausgehen, sondern grundsätzlich alle möglichen Ausnahmen in Betracht ziehen. So ist es z.B. notwendig, für `Hausnummer` einen Text-Typ zu wählen, da z.B. ,,5a`` auch eine gültige Hausnummer ist.
![]()
![]()
![]()
![]()
![]()
Up: Theoretische Grundlagen
Previous: Datenbanksystem
Next: Praktischer Teil SQL
![\includegraphics[width=15cm]{images/ER-Bsp1}](img5.png)
![\includegraphics[width=15cm]{images/ER-Bsp2}](img6.png)